External Fingerprint Storage Phase-2 Updates

As another great phase for the External Fingerprint Storage Project comes to an end, we summarise the work done during this phase in this blog post. It was an exciting and fruitful journey, just like the previous phase, and offered some great learning experience.
To understand what the project is about and the past progress, please refer to the phase 1 blog post.
New Stories Completed
We targeted four stories in this phase, namely fingerprint cleanup, fingerprint migration, refactoring the current implementation to use descriptors, and improved testing of the Redis Fingerprint Storage Plugin. We explain these stories in detail below.
Fingerprint Cleanup
This story involved extending the FingerprintStorage API to allow external storage plugins to perform and configure
their own fingerprint cleanup strategies.
We added the following functionalities to Jenkins core API:
-
FingerprintStorage#iterateAndCleanupFingerprints(TaskListener taskListener)-
This allows external fingerprint storage implementations to implement their own custom fingerprint cleanup. The method is called periodically by Jenkins core.
-
-
FingerprintStorage#cleanFingerprint(Fingerprint fingerprint, TaskListener taskListener)-
This is a reference implementation which can be called by external storage plugins to clean up a fingerprint. It is upto the plugin implementation to decide whether to use this method. They may choose to write a custom implementation.
-
We consume these new API functionalities in the Redis Fingerprint Storage plugin. The plugin uses cursors to traverse the fingerprints, updating the build information, and deleting the build-less fingerprints.
Earlier, fingerprint cleanup was always run periodically and there was no way to turn it off. We also added an option to allow the user to turn off fingerprint cleanup.

This was done because it may be the case that keeping redundant fingerprints in memory might be cheaper than the cleanup operation (especially in the case of external storages, which are cheaper these days).
Fingerprint Migration
Earlier, there was no support for fingerprints stored in the local storage. In this phase, we introduce migration support for users. The old fingerprints are now migrated to the new configured external storage whenever they are used (lazy migration). This allows gradual migration of old fingerprints from local disk storage to the new external storage.
Refactor FingerprintStorage to use descriptors
Earlier, whenever an external fingerprint storage plugin was installed, it was enabled by default.
We refactored the implementation to make use of Descriptor pattern so the fingerprint engine can now be selected
as a dropdown from the Jenkins configuration page.
The dropdown is shown only when multiple fingerprint storage engines are configured on the system.
Redis Fingerprint Storage Plugin was refactored
to use this new implementation.
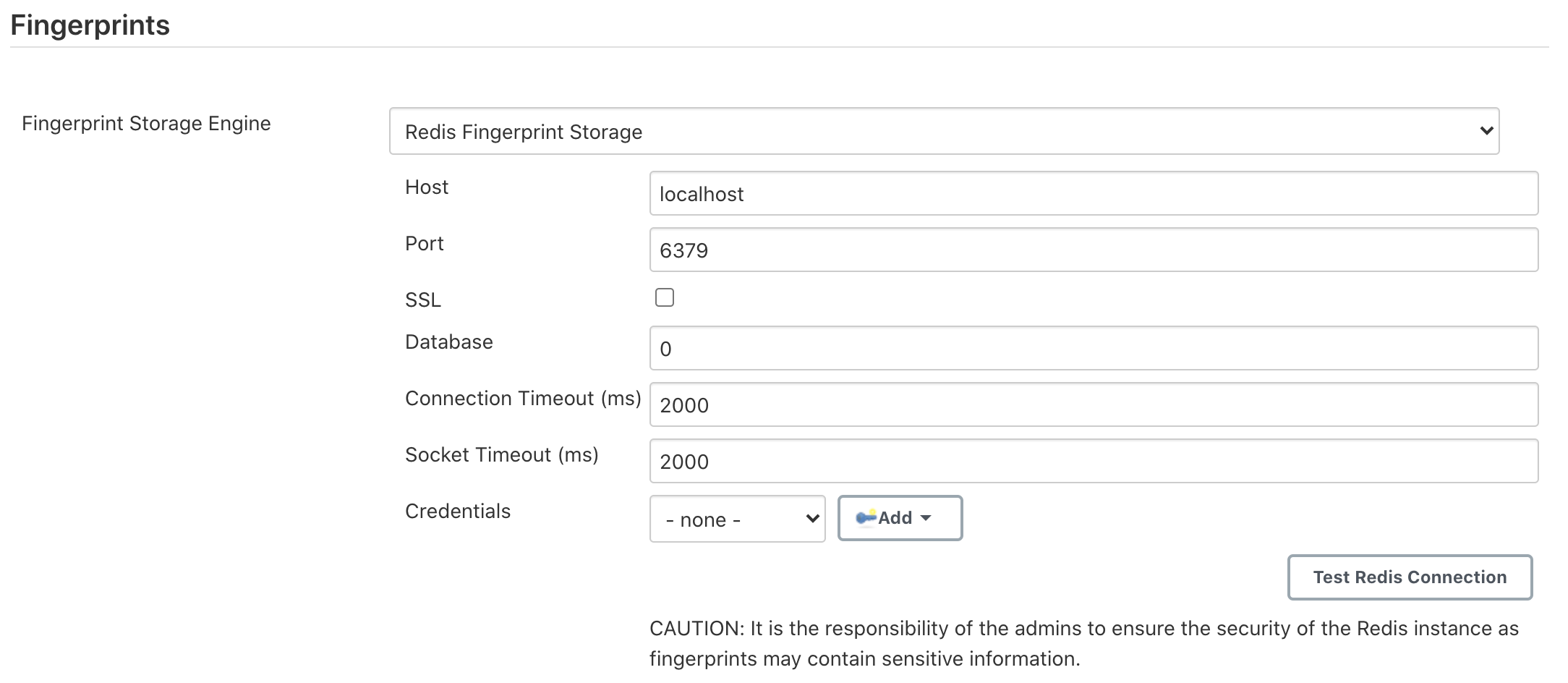
Strengthened testing for the Redis Fingerprint Storage Plugin
We introduced new connection tests in the Redis Fingerprint Storage Plugin. These tests allow testing of cases like slow connection, breakage of connection to Redis, etc. These were implemented using the Toxiproxy module inside Testcontainers.
We introduced test for Configuration-as-code (JCasC) compatibility with the plugin. The documentation for configuring the plugin using JCasC was also added.
We introduced a suite of authentication tests, to verify the proper working of the Redis authentication system. Authentication uses the credentials plugin.
We strengthened our web UI testing to ensure that the configuration page for the plugin works properly as planned.
Other miscellaneous tasks
Please refer to the Jira Epic for this phase.
Releases 🚀
Changes in the Jenkins core (except migration) were released in Jenkins 2.248.
We drafted 1.0-rc-1 release for the Redis Fingerprint Storage Plugin to deliver the changes. This was an increment from the alpha release we had drafted at the end of the previous phase. The plugin is now available at https://plugins.jenkins.io/redis-fingerprint-storage/!
Trying out the new features!
The latest release for the plugin can be downloaded from the update center, instructions for which can be found in the README of the plugin. We appreciate you trying out the plugin, and welcome any suggestions, feature requests, bug reports, etc.
Acknowledgements
The Redis Fingerprint Storage plugin is built and maintained by the Google Summer of Code (GSoC) Team for External Fingerprint Storage for Jenkins. Special thanks to Oleg Nenashev, Andrey Falko, Mike Cirioli, Tim Jacomb, and the entire Jenkins community for all the contribution to this project.
Future Work
Some of the topics we aim to tackle in the next phase include a new reference implementation (possibly backed by PostgreSQL), tracing, etc.
Reaching Out
Feel free to reach out to us for any questions, feedback, etc. on the project’s Gitter Channel or the Jenkins
Developer Mailing list.
We use Jenkins Jira to track issues.
Feel free to file issues under redis-fingerprint-storage-plugin component.
About the author