Building a Serverless CI/CD Pipeline with Jenkins

As with any new hyped-technology the term 'serverless' is often overloaded with different meanings. Sometimes serverless is oversimplified to mean function-as-a-service(faas). But there is more to it than that. Also, not many people are talking about doing CI/CD with serverless, even though where there is code there still in need of continuous integration and continuous delivery. So I was excited to hear about this talk by Anubhav Mishra on Building a CI/CD Pipeline for Serverless Applications.
In the talk Anubhav proposes a new definition for serverless:
"" Serverless is a technology pattern that provides services and concepts to minimize operational overhead that comes with managing servers. It is a powerful abstraction when used can result in an increased focus on business value. ""
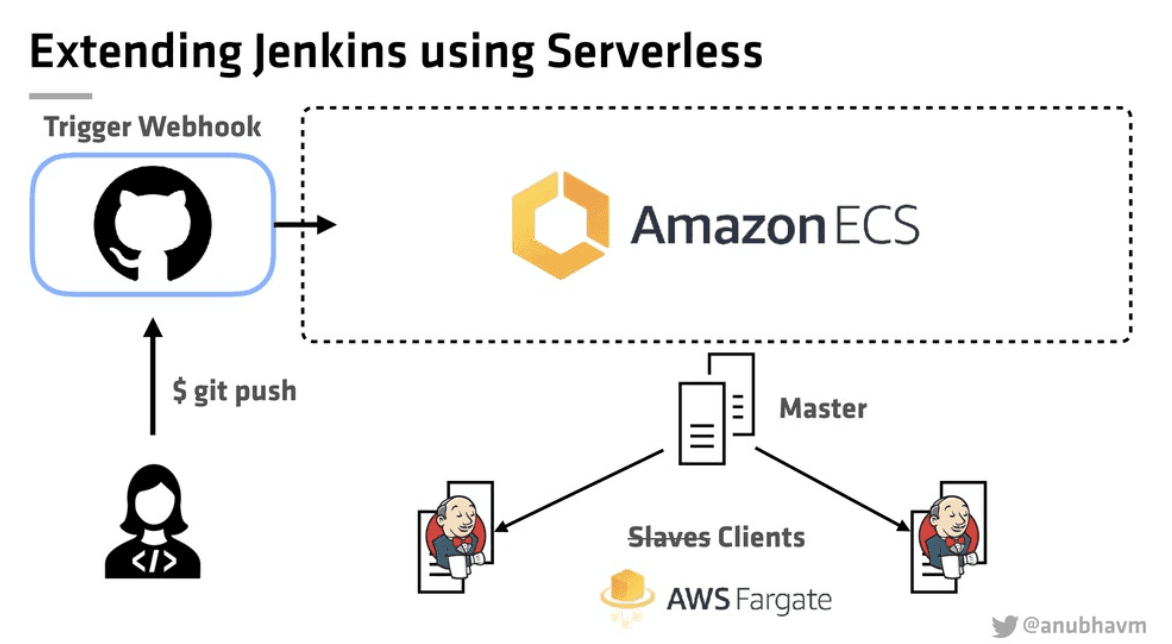
The talk then goes on to demo Jenkins on AWS Fargate (a platform for running containers without managing servers or clusters). The main focus is on increased elasticity/scaling.
The advantages of this approach are:
-
No nodes/servers to manage
-
Launch 10,000+ builds/containers in seconds
-
No cost for idle time
The real headline is the cost saving, which is 2 orders of magnitude better with serverless. A cost comparison is done based on 1 vCPU & 2GB memory:
-
With Jenkins on Fargate: 100 builds * 5 mins = $0.633/month
-
With Jenkins on EC2 Instances: ~50/month
This huge potential cost saving is one of the things that makes serverless incredibly compelling. Not to mention you don’t have to think much upfront about scaling the system.
But there are drawbacks with this approach, noted as:
-
Cold starts - slower boot times for clients
-
Large container images (~1G)
-
No root access
-
Ephemeral storage (default)
This is an area where Jenkins can continue to evolve to make the most of serverless architectures. I highly recommend you check out the slides for yourself. The best part is that, in the true spirit of open source, Anubvha shared the code here. So you can give it a try yourself and build your own serverless CI/CD pipeline with Jenkins.
About the author